



 01
01
物体识别在人工智能界非常多见,但其前提在于大量数据的“喂给”。殊不知,在高大上的人工智能背后,却是数据标记员大量“纯人工”苦力活。那么,有没有可能,让机器像人脑那样能够融会贯通、举一反三,从而减少对海量数据的依赖?在世界智能大会的应用体验区——油罐艺术中心内,记者看到了端倪。
即便身处酒吧,也可以一键P成在办公室加班的样子;一张照片中有多人“乱入”,但一步就能将多余的人去掉且了无痕迹,再不用去求P图高手。这是记者在世界人工智能大会应用体验区——油罐艺术中心5号罐Versa展位看到的一幕。

海滩上多余的人被一键P除。
这款应用,名叫“马卡龙玩图”,目前在苹果商店中排名居前,其在照片与视频制作中大有用武之地,但其核心本领,在于“带有语义的识别”。该展位工作人员黄之炜向记者解释,“也就是说,机器能理解画面中物体间的差别,从而进行分割和智能填充。譬如说,照片中你想去除的人,其身后是沙发,那么,在把此人去掉的同时,机器会智能地将原本占位的地方恢复成沙发。”

“马卡龙玩图”的智能填充功能。
但如此聪明的前提,在于人工智能必须明确辨识照片中的不同物体,这就引出人工智能中一个话题——没错,现在大数据太火了,而且数据越多,机器的深度学习就会越精准。然而海量数据,意味着巨大代价。譬如2014年,国际知名科技公司动用了1000万照片和1000台电脑运算,才让机器识别了猫。近年来随着算法的进步,主流人工智能公司识别一个具体物体的平均数据量已减少到8万个。殊不知,在高大上的人工智能背后,都是数据标记员大量“纯人工”苦力活,他们根据项目方要求,人工为图片、视频和语音内容打标签、做标记,再被人工智能公司用来训练算法模型。然而,这家Versa公司换了一种方法来识别猫,其数据竟可“精简”到500个!
当下,各国都越来越重视“数权”,未来,数据都要卖钱了。在此背景下,这家公司对数据的高利用率无疑将转化为实在在的竞争力。更何况,在某些应用场景数据有限,已经很难找到千万、百万甚至十万级的数据。正如Landing.AI创始人及首席执行官吴恩达所言:“数据当然是越多越好,我也并没有说许多数据是无用数据。但是,在农业、制造、医疗等领域的部分应用场景中,譬如一些脑肿瘤疾病,数据少到只有100张,你怎么办?”
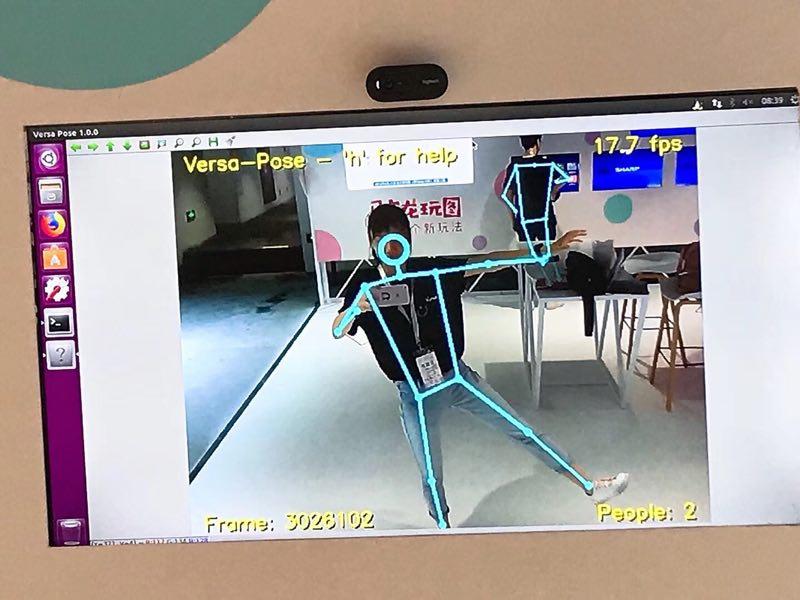
“马卡龙玩图”的姿势识别,即便你手放在身后,聪明的机器也能“推理”出你手的位置。
据介绍,Versa公司去年4月在沪成立,其创始团队包括前格瓦拉产品合伙人蔡天懿、前华为海思芯片算法科学家赵维杰等。该公司的类脑科学,摆脱了对海量数据的过分依赖,它或许代表着AI算法研究中的一种创新算法。目前,该公司的算法能直接辨认30余种物体,今后将立志于实现通用智能,也就是让机器像人类一样思考,不仅能识别纸和书的不同,还能知道红纸和白纸的差别。
正如该公司首席技术官赵维杰的一句话:“就好比我们并不鼓励同学们死记硬背考高分,而是鼓励理解和认知,只有做到融会贯通,人工智能才会变得更聪明。”
【编辑:朱艳琳】
请输入验证码